
DeepSeek V3.2-Exp deep dive
Making Long Context Affordable Without Sacrificing Intelligence

On 29 September DeepSeek released DeepSeek V3.2-exp, it feels like an eternity ago, but only 1 month has passed. It was an experimental approach for improving the context window, that I think was really interesting and wanted to study in deep.
The challenges of handling long-context inputs in large language models is not trivial. Dense self-attention mechanisms, which consider every previous token as potentially relevant, lead to quadratic growth in computational costs during prefill and repeated accesses to massive KV caches during decoding. Even if there are some interesting approaches to improve this problem, DeepSeek’s latest release, V3.2-Exp, addresses these issues with a really interesting approach.
They tackle it by building on the V3.1-Terminus foundation and introducing what they called DeepSeek Sparse Attention (DSA), a learned, content-aware router placed before the attention layers. This innovation maintains comparable quality while significantly reducing costs for long-context operations, resulting in a launch-day API price reduction of over 50%. To help illustrate how this works, I’ve incorporated two hand-drawn sketches that break down the architecture, training, mechanism, and results. Let’s dive in.
The Unchanged Core: MLA Foundation
V3.2-Exp isn’t a complete overhaul; it preserves the Multi-head Latent Attention (MLA) architecture from the V2-series, first introduced in V2 and refined in V3 and V3.1 (we will see MLA in deep in another post). MLA efficiently compresses key-value projections, reducing KV footprint and bandwidth demands (improving the inference time, for example). DSA acts as a selective gateway to these existing attention blocks, ensuring architectural continuity, behavioural consistency, and straightforward upgrades for users.
Architecture Compatibility and Training
As we can see in Sketch 1 below, V3.2-Exp maintains strong compatibility with V3.1 through its use of MLA in Multi-Query Attention (MQA) mode. This setup shares a single KV latent vector per token across all query heads, allowing old weights to load seamlessly. DSA essentially wraps the attention mechanism like a routing layer, deciding which KV entries from the past context are worth attending to, without altering the underlying structure.
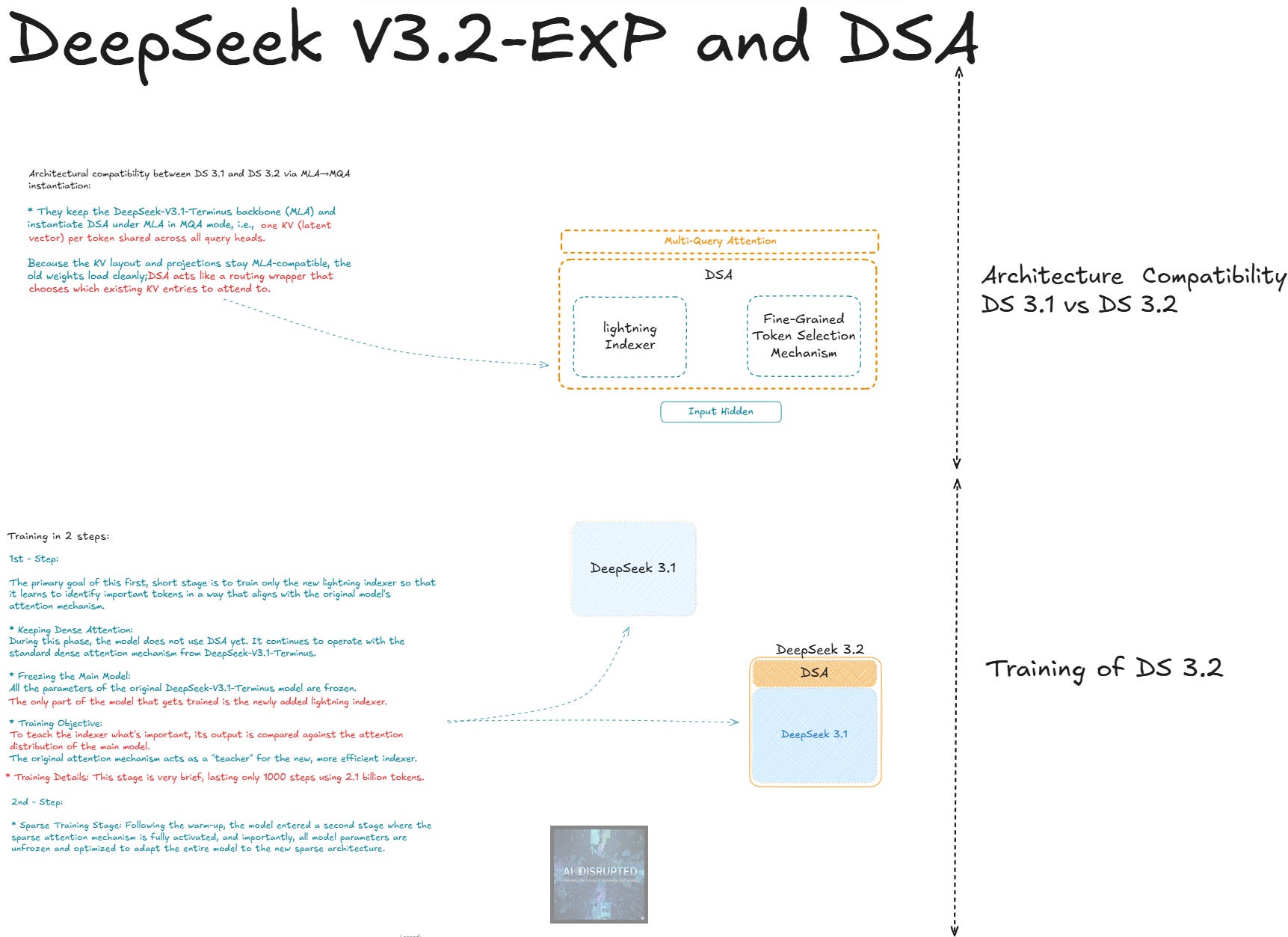
In the sketch we can see DSA’s two main components:
Lightning Indexer: This provides a fast, approximate pass to score relevance over past positions from the current hidden state, selecting a dynamic top-k candidate set based on content.
Fine-grained Token Selector: A small learned scorer that refines those candidates, often per head, to form the final shortlist for attention.
This design keeps the backbone intact while adding sparsity, which I think is really smart because they can re-use DeepSeek V3.1 training and testing the new approach. The training process, also depicted in the sketch, unfolds in two steps for efficiency:
Step 1 (Indexer Alignment): The primary goal here is to train only the new Lightning Indexer so it learns to identify important tokens in a way that aligns with the original model’s attention mechanisms. During this phase, the model does not use DSA yet; it continues to operate with the standard dense attention from DeepSeek-V3.1-Terminus. All parameters of the original DeepSeek-V3.1-Terminus model are frozen. The only part of the model that gets trained is the newly added Lightning Indexer. To teach the indexer what’s important, its output is compared against the attention distribution of the main model. The original attention mechanism acts as a “teacher” for the new, more efficient indexer. This stage is very brief, lasting only 1,000 steps using 2.1 billion tokens for the warm-up.
Step 2 (Sparse Finetune): Following the warm-up, the model enters a second stage where the Lightning Indexer is partially used to help the entire model adapt to the new, sparser architecture. All parameters are unfrozen and optimized.
By building directly on V3.1-Terminus this way, the update minimizes disruptions while isolating the benefits of sparsity.
How DSA Works and Results
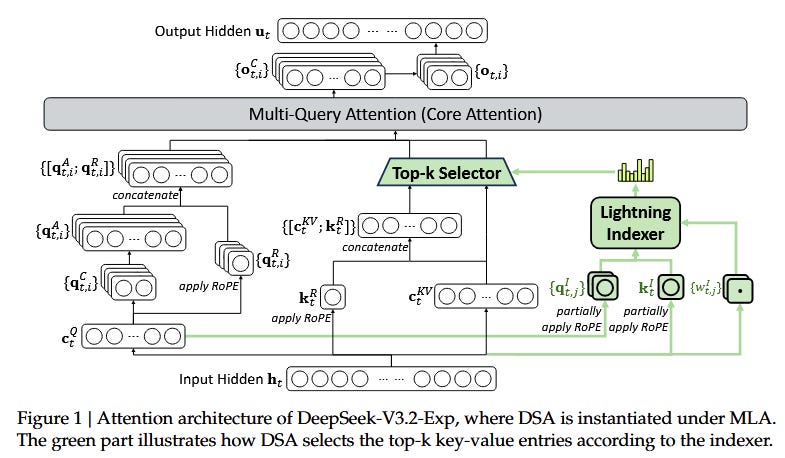
Turning to Sketch 2, it walks through the DSA mechanism at inference time for each generated token, starting from the input hidden state (H_in). The flow is clear: a coarse pass via the Lightning Indexer, refinement with the Fine-grained Token Selector, and then exact attention only on the shortlist, all while leveraging the MLA backbone to keep cache accesses minimal, especially in long contexts.
Here’s the step-by-step breakdown, as illustrated:
Coarse Pass (Lightning Indexer): From H_in, compute small features (tiny projections, not per-head). Output scores (I) over all past positions to get top-k candidates, dynamic and query-dependent, not a fixed window. Optimizations like FP8 precision, ReLU, and Hadamard products keep this fast despite O(L) scoring.
Precise Pass (Fine-grained Selection): Gather latents (c_latent) from the candidate set in the MLA cache. Use a tiny scorer to output the selected shortlist (c_sel), size k, potentially head-specific.
Exact Attention (MQA): Make the usual queries (Q) from H_in with RoPE. Attend only to the shortlist’s shared K/V from c_sel (not the whole prefix). The attention result (U) feeds into residual + MLP, just like a standard block.
This selective approach is why quality holds up: the model learns to fetch what’s truly relevant, even if it’s distant.
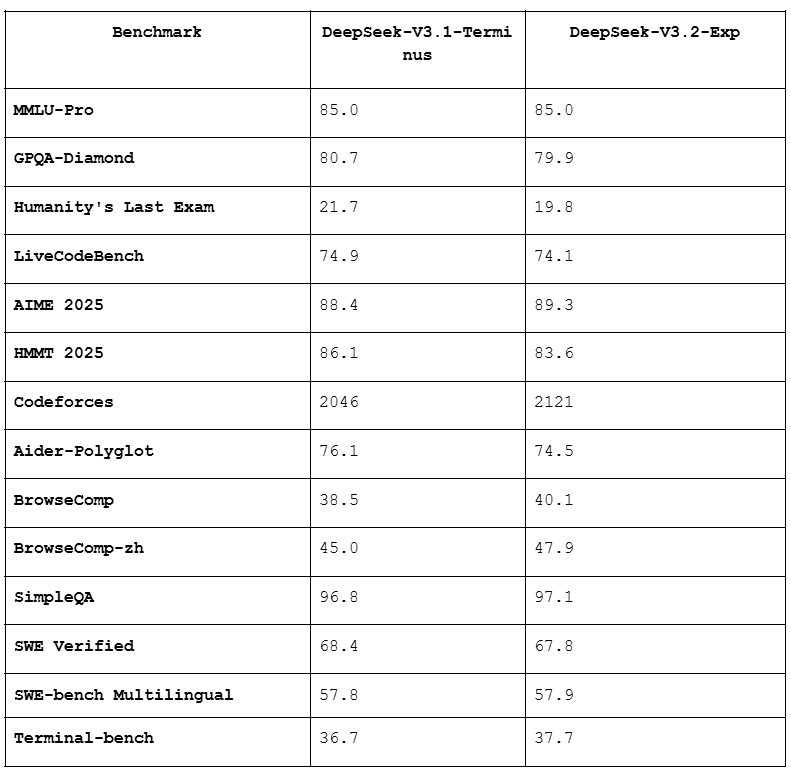
Quality Maintenance
As shown in the benchmark table in Sketch 2, V3.2-Exp delivers performance on par with V3.1-Terminus across a range of evaluations, with no substantial degradation. Some minor dips (e.g., in GPQA or Humanity’s Last Exam) occur because V3.2 generates fewer reasoning tokens, but wins in areas like AIME 2025 or Codeforces rating. Here’s the full comparison for reference:
Economic Benefits
The graphs in Sketch 2 tell the efficiency story best: while V3.1’s costs (measured on H800 GPUs at $2/hour) rise steeply with token position in both prefill and decoding, V3.2-Exp’s curves stay much flatter thanks to dynamic sparsity. At 128K tokens, you can see savings up to 78% in decoding alone. This directly enabled the API price cut, opening up long-context use cases like RAG or multi-document workflows to more users.
Pragmatic Design Choices
Minimal Disruption: As Sketch 1 illustrates, it reuses V3.1 weights and MLA cache geometry, the router is a non-invasive add-on, making adoption and potential rollbacks straightforward.
Learned Sparsity: DSA’s dynamic, per-token and per-head selection (Sketch 2) outperforms rigid patterns, pulling in non-local evidence when it matters to keep quality dense-like.
Long-Context Focus: The longer your input, the bigger the wins, perfect for retrieval-intensive apps.
Adoption Considerations
Critical Tasks: In high-stakes scenarios where missing a key detail could hurt, build tests for rare, distant references in large contexts.
A/B Testing: Reuse the same prompts, seeds, and settings to compare V3.2-Exp against V3.1 archives if available.
Serving: With MLA intact, caching stays familiar, but latency improvements shine in extended sequences.
There are some Open-source support via kernels like TileLang, DeepGEMM, and FlashMLA makes deployment easy on Hugging Face, vLLM, or SGLang.
Broader Implications
V3.2-Exp marks a step in AI’s efficiency evolution: moving beyond “bigger is better” to “smarter is cheaper.” By letting the model decide what to attend to (as visualized in these sketches) it makes long-context capabilities practical and affordable. Built atop V3.1-Terminus with DSA and a matching price drop, it’s a pragmatic bridge to future innovations.
Sources
DeepSeek Announcement: https://api-docs.deepseek.com/news/news250929
V3.2-Exp GitHub: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp
V-series GitHub: https://github.com/deepseek-ai/DeepSeek-V3
Reuters Coverage: https://www.reuters.com/technology/deepseek-releases-model-it-calls-intermediate-step-towards-next-generation-2025-09-29/